8 Lessons in Machine Learning
- Lisa Hemme
- Oct 2, 2018
- 11 min read
My apologies, as it has been MONTHS since I have written a blog. I appreciate all of you who read them and give me feedback, it is much appreciated.
It was my intent to write this article after we had a grand success in machine learning technologies early this summer and I would enlighten everyone to the endless possibilities of what machine learning can do for all of you. However, we really didn't get a rousing success, but we also didn't have a complete and miserable failure. We learned a lot, and still have a LOT to learn in this area.
I have also had a bit of a writer's block as to what to write about if I didn't write about this subject. Today, I am actually writing three posts, so I guess my block has eased!

I am going to just give you what we have learned so far. This blog is not written from a perspective of "we are experts and listen to us," but from a perspective of "we are out here pushing the envelope and struggling at times, and here is our journey." I hope that this helps you. I will be as transparent as I can, and I will be more transparent on our struggles than about our customer's problem.
The problem we took on was one where our customer had a contamination issue. It was literally the most daunting, complex, and costly issue that our customer faces on a daily basis. They have struggled with it for the last 7 years, and had made minimal strides in understanding where the contamination comes from. They have learned a few things that do help them understand that a contamination event may be about to occur and they have learned to better mitigate its effects, but they still needed improvement in speed and certainty of identifying the problem.
The challenges were and are many with this particular problem:
The confirmation of the contamination issue is by a laboratory sample that is taken every 4 hours. This lab sample takes an hour or more to process.
The samples are taken 4-6 hours downstream process-wise from where the contamination could have entered the plant.
The customer, over many hours of investigation, had noticed several sensors that would exhibit a certain behavior in the process several hours ahead of the contamination confirmation from the lab (but not always the same time lag).
The customer had measures in place that if these observations were true, that the operator could take action, which when building the model for the data, would have significant impacts to the time lags observed and to the potential severity of the issue.
Since this is literally the hardest problem that this customer faces and it is worth a lot of money to them if the problem were to be solved, I thought it was a perfect place to start with machine learning tools. Well, I was wrong, and I was right as well. It was very frustrating because at times we believed we weren't making any progress on a solution, yet we were learning a lot the whole time. I won't go into the tools we used nor will I expose all we did, but there were lessons learned. I will share these lessons with you below.
1. Subject matter expertise is still REALLY important
If this company's SMEs hadn't noticed several leading indicators of the contamination issue, I am not sure we would have found anything with any of the tools we used. I have a discussion set up with one of the vendors tomorrow to discuss this point in greater detail, but to me, these few observations helped us in every machine learning investigation that we did. The two sensor readings that went amiss leading up to the lab confirmation of the contamination event had anywhere between a two and a half hour and a sixteen and a half hour time lag between the sensor anomaly and the lab confirmation of contamination. Most, if not all, machine learning tools would need some help in understanding this varied relationship and time lag, as trying to run all of the different permutations on the data and time lags is just impractical. If they hadn't observed this phenomenon, I am just not sure we would have discovered anything with the machine learning tools since the time lags were so drastically different.
Again, maybe there are some different techniques that could be used, and we will delve further into them starting tomorrow.
Subject matter experts also helped us determine what was simple correlation versus what could be causation. Machine learning tools and data scientists can be great at picking up correlation, but don't always understand causation, which is what we are all looking for in these investigations. That isn't a knock, but data scientists and machine learning tools have a different role in this game we are playing, and that is okay, just don't minimize the needs for SMEs on your process. Too many companies selling machine learning tools will tell you that they don't need SMEs on the process to solve the problem. Don't believe them.
There are likely other problems that we could look at where subject matter expertise wasn't as critical, but for this problem, and many that we have looked at investigating, we would need a subject matter expert who understand the physical process or we simply won't be successful.
To me, the data scientists and machine learning tools need to help the SMEs with ideas that they would never have thought of, or correlations that they didn't fully understand or see. They need to make all of us say "huh, I wouldn't have thought of THAT. Let me further investigate because there could be something to that discovery."
2. SME's and data scientists don't speak the same language
Data scientists are often (an I use this endearingly) "math nerds" and more times than not, don't understand the physical process of how something is made. That isn't a knock, but it isn't their job or their passion.
On the other hand, operations people tend to be "process nerds." They fully understand their manufacturing process and live it and breathe it.
The languages that these two use in their area of expertise are drastically different. Data scientists don't often understand chemical reactions, interactions in physical machinery, and the like, nor do they care in most cases.
Operations people don't care about regression trees, data binning, feature selection, feature engineering, and the like. They sometimes don't even have advanced mathematical backgrounds, or if they do, it has been years since it has been put in practice.
Someone has to have enough knowledge of each area to explain to the other party why something is so important to the other side. That seems to be a role we are playing well and will likely to play in the future. We know enough to be dangerous in both, and we are subject matter experts in time-series data. This leads me to my third lesson.
3. It is harder to apply machine learning tools to time series data
I stated this to a CIO recently, and he inquisitively asked me "why?" Well, time series data comes at us in all different cadences. We get some data that is scanned every 10 seconds, others every minute, others every hour, others supposedly every 4 hours, but not necessarily like clockwork. It isn't like transactional or relational data, where everything comes in one "bucket" or one row. Just because the data is scanned at those intervals, doesn't mean that they are stored in those intervals, depending on the compression techniques used. So, the data comes in unevenly, and machine learning techniques generally need evenly spaced data, or, at worst, there is only one timestamp for all data points in the investigation. These tools can't operate where some data comes in every 10 seconds and other data comes in every 15 minutes.
Actually, let me make a slight correction. These tools CAN handle gaps in data, depending what techniques are used. In the below picture, scenarios 2-4 can be handled. Scenario 1 can not. Here is a quick description in case the pictures are tough to see:
Scenario 1: Tag 1 has a timestamp every 10 seconds and tag 2 has a timestamp every minute. None of the tools we tested could handle many different timestamps like this.
Scenario 2: Tag 1 is sampled every minute and lined up with the timestamps from tag 2.
Scenario 3: Tag 2 has gaps for the missing data, and only has data for the 1 minute timestamps. The 10 second data is just left blank.
Scenario 4: This is the one we often use. It is like scenarios 2 and 3 combined, except that we assume linear interpolation between the points we actually have data for on tag 2, and sample the values on tag 1 like scenario 2, if required. In this case, let's say we wanted a 30 second sample, we would take the sampled data for tag 1, and interpolated data for tag 2.
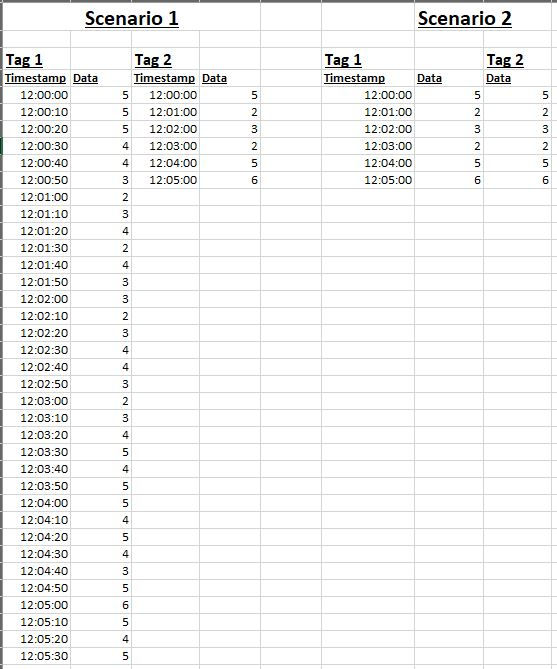

Again, any machine learning tool worth its salt can handle scenarios 2-4 with ease, you just have to decide which is best for your situation.
We also have to make a determination on what fidelity to get the data, what to do with repeat data and what to do with gaps in the data as shown above.
This above problems are not usually issues with transactional or relational data.
4. Data fidelity is CRITICAL
The first dataset that we pulled to investigate the contamination problem was for a few thousand tags at 1 hour intervals. After looking at the data, running through the first machine learning evaluations, and then in more intense discussions with SMEs, we found that we needed a minimum of 5 minute intervals. We also determined that we needed at least 18 months of data to get a complete picture for the machine learning tools. Our final dataset was 232 tags at 5 minute intervals for 18 months, which became a 360 Megabyte .CSV file. We questioned if we needed 1 minute intervals for a long time, but decided on 5 minute intervals after lots of investigation. If your data fidelity is too low, you don't get the answers you need. If the data fidelity is too high, your data becomes unwieldy and analyses take forever and may not give you any more information.
5. Data quality is even more CRITICAL
I can't stress this enough. I have written on data quality in the past here and I won't belabor the points made in that article now. However, there are things to consider.
One of the observations made by one of the SMEs that we worked with was that there was a certain sensor reading that was a critical piece of evidence to determine that a contamination event was imminent. What we noticed was that the first two contamination events in our investigation had "over compressed" data for this sensor reading and we couldn't really see the subtle changes in that signal that told us of an impending event. In other words, a drop from 3.11 to 3.09 was actually very significant for this signal. For most other signals, this is quite insignificant.
We could now say that the data for this signal is "under compressed" and we get almost every measurement, which may lead to some noisiness in that signal, but we needed it because a subtle change in the sensor data told us a lot about the process. This discovery also changed how we pulled the data (I didn't do 5 minute averages because of a signal like this - it was taken 6 times a minute, so to get one value, we needed to average 25-30 readings per row of data we kept over the course of a year and a half, and we determined this was overkill).
If they hadn't changed the compression on this tag to get more high fidelity data, we simply couldn't have used it in our analysis. We also ended up finding many other tags in their system that are "over compressed" (i.e. one to two sensor readings per day) and told us almost nothing. Did that hurt us? We don't know for sure.
6. The math had to match the physics and chemistry
The first company we worked with on this issue did pretty extensive analysis on this dataset. They weren't able to "tell us what we already knew" (what the customer had already observed), yet they kept telling us things "that we didn't know." At one point, they told us they saw a pattern 3-12 days before the contamination events based on some data in a certain area of the plant.
I told them that it was the equivalent of my doctor telling me that I get violently ill several times a year because I eat shrimp 3-12 days before I get ill. Interesting observation, but I think that whatever potential problems I got from eating the shrimp would be long gone by day 3 after eating it, so we had correlation and not causation here.
In this case, the "prediction" didn't match what was physically possible in the process. This will happen fairly often in machine learning investigations, and is just part of it. This isn't a knock on that company or their algorithms, but it points out several points above - SMEs are critical, and the "math nerds" and "process nerds" don't necessarily operate on the same wavelength.
It could have been just as likely that this was a key observation that no one had thought of before, so you really need to run down any potential correlations found by the machine learning tools and make sure it makes sense to investigate it further or to eliminate it altogether.
7. Algorithms matter
It is interesting to me that most of the mathematical tools using in machine learning tools have been around for years. Some were developed as the 50's, some in the 80's and 90's, and a few are more modern than that. In general though, the math hasn't changed much.
Probably our biggest challenge and our biggest area of study over the next several years will be which algorithms work on which problems and why. How do we tune those algorithms to get the right answers? When do we use some type of regression tree and which type? When do we use data binning? When should be go to a multi-variate model like principle component analysis (PCA) or partial least squares (PLS)?
However, we definitely noticed that some algorithms got us much closer to what we already knew and brought us more interesting ideas to chase down. Some of them flat didn't tell us anything of note.
8. Human intervention and interaction can blow up your model
In working with this customer, we found out that their operators often take action based on observations that they had made before we started using machine learning tools. So, instead of continuing to run the process to "failure" or to a contamination event, they take steps to lessen its effects or avoid it altogether. Therefore, the events from years ago won't look like the events over the last 6-8 months, because humans intervene to try to change the outcome. This makes mathematical simulation much more difficult. Human intervention and modeling this intervention will always be a challenge.
Again, this was a point made by our main SME on this process. We wouldn't have known about the operator intervention without his knowledge that he passed on to us.
In conclusion
Machine learning tools have tremendous upside and they will become more and more used in the manufacturing world. We already see these tools in our every day lives whether we know it or not. Why do you think we get certain ads when we browse the internet? How does Gmail or LinkedIn suggest answers to a message I just received? Yup, algorithms, machine learning, artificial intelligence, et al.
Our challenges are unique in the manufacturing world as the datasets, time lags, and interactions between variables are tougher to determine; plus all of the lessons learned above will need to be overcome. I think there are many, much simpler use cases out there that lighter weight ML tools will be used on and will show great value.
We will continue pursuing these technologies and let all of you know what we see and experience. Please, share your experiences as well!